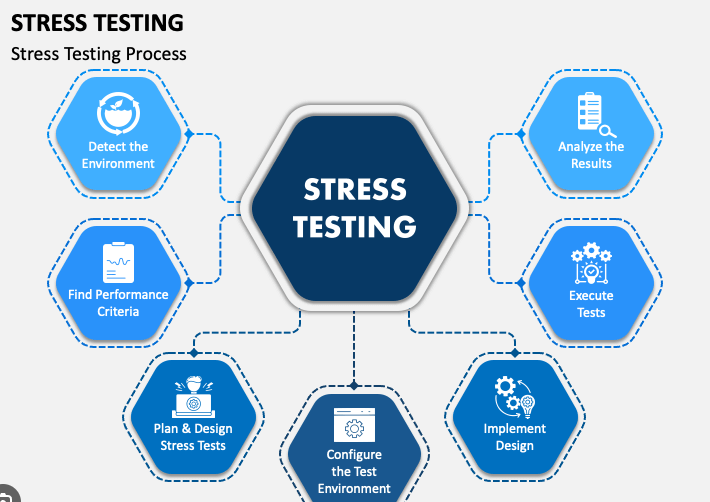
스트레스 테스트 설계
- 스트레스 테스팅은 소프트웨어를 의도적으로 비현실적인 부하에 놓이게 하여 주요 시스템 리소스 사용을 방해함. 스트레스 하에 놓인 시스템의 저하된 성능이 당연하게 받아들여질 수도 있으므로 테스트 결과의 해석과 성공/실패 기준의 정의가 타 테스팅에 비하여 더 주관적임
- 본 논문은 아래 그림과 같은 스트레스 테스트 설계 방식을 사용함. 즉, 전체 테스트 시작 시점에 CPU 부하가 점차 증가되고, 높은 부하 상태의 프로세서에서 일련의 테스트들이 수행되며(개별 테스트를 ‘서브테스트’라 지칭), 일련의 서브테스트들이 완료되면 CPU가 정상 수준으로 되돌려짐
- 테스트 스크립트를 확인하고 그것이 소프트웨어 스트레스 테스트로 통합되기 전에 기준 동작(baseline behavior)을 세우기 위해서 서브테스트가 (시스템이 스트레스 하에 있지 않은 상태에서) 독립적으로 개발되고, 디버그되고, 실행될 수 있음

[소프트웨어 스트레스 테스트의 구조]
적절한 타겟 CPU 부하는?
- 소프트웨어를 스트레스 하에 놓는 방식의 하나로 CPU 부하를 증가시키걸 들 수 있음
- 특히 프리엠션 멀티태스킹 시스템(pre-emptive multitasking systems)을 스트레스 테스팅 할 때 CPU 부하를 증가시키는게 중요. 프리엠션 시스템에서는 모든 실시간 데드라인이 충족되는걸 보장하기 위해서 소프트웨어 설계자가 태스크 우선 순위 할당에 상당한 노력을 기울이게 되는데, 태스크 우선 순위가 형편없이 할당되었다 하더라도 전체 CPU 부하가 약 85% 미만이면 태스크 데드라인이 대개 충족되는 것으로 알려짐. 다른 말로 하면 15%의 자유로운 CPU 부하가 있으면 태스크 우선 순위 할당과 관련한 결점을 덮을 수 있는 충분한 여유가 제공된다는 의미
- 스트레스 테스트의 목적 중 하나가 이러한 결점을 찾아내는 것이므로 테스트에서 타겟 CPU 부하가 가능하면 90% 이상이어야 함
시스템에 스트레스를 주는 다른 방식들
CPU 부하를 증가시키는 것 외에 소프트웨어 시스템에 스트레스를 주는 방식으로 아래와 같은 것들이 있다.
- 입출력 데이터율 최대화(Maximizing I/O data rates)
- 데이터 버스 사용 최대화(Maximizing data bus usage)
- 인터럽트율 최대화(Maximizing interrupt rate)
- 가용 메모리 고갈시키기(Exhausting available memory)
- 큐 오버플로우 시키기(Overflowing queues)
현실 소프트웨어에 스트레스 테스팅 적용
- 존 홉킨스 대학의 응용 물리학 연구실(JHU/APL)에서 3개의 NASA 미션을 위한 우주선 비행 소프트웨어를 개발함(아래 표 참조). 이 임베디드 소프트웨어가 “critical”하며(심각한 결함은 미션 실패를 낳을 수 있음), 수 년의 장기간 동안 지속적으로 운영될 필요가 있음
- 3개 소프트웨어 모두 공식 소프트웨어 개발 생명 주기(요구사항 분석, 설계, 구현, 단위 및 통합 테스팅, 요구사항 기반 테스팅, 시스템 수준 승인 테스팅을 포함)를 따라 개발되었으며, 이 논문에서 기술한 것과 같은 소프트웨어 스트레스 테스팅이 소프트웨어 생명 주기 막판에 수행됨
- 스트레스 테스트를 개발하고 실행하는데 요구된 노력이 다른 개별 승인 테스트에 들어간 노력보다 훨씬 컸으며(스트레스 테스트가 전체 소프트웨어 승인 테스트 노력의 약 10%를 차지), 스트레스 테스팅 동안 3개의 소프트웨어 개발에서 총 32개의 문제가 발견됨
| 미션 | 발사일 | 기간 |
| MErcury Surface, Space ENvironment, GEochemistry, and Ranging (MESSENGER) | 2004년 8월 | 8년 |
| New Horizons (Pluto-Kuiper Belt Mission) | 2006년 1월 | 9년 이상 |
| Solar TErrestrial RElations Observatory (STEREO) | 2006년 10월 | 2년 이상 |
스트레스 테스팅에서 발견된 32개의 문제 중 4개 결함에 대한 자세한 분석 결과가 아래와 같다.
결함 사례 #1: CPU 부하가 높을 때 소프트웨어가 일부 커맨드를 수신하지 못함
- CPU가 과부하까지는 아니지만 높은 부하를 가지는 동안(> 90%) 가능한 최고율로 1000개의 커맨드 스트림을 소프트웨어로 발생시키는 스트레스 서브테스트가 설계됨. 이 커맨드들이 하드웨어 버퍼에 들어가게 되고, 소프트웨어는 덮어쓰기가 일어나기 전에 버퍼를 서비스 해야 함
- 스트레스 서브테스트 동안에 CPU 부하가 100%에 도달한 적이 없었음에도 불구하고 1000개 커맨드 중 5개가 누락됨
- 커맨드들이 수신되는 동안에 CPU 사용이 100%로 치솟았다면 이런 커맨드 누락이 성능 저하로 인한 납득가능한 행동이었을지도 모름. 하지만 여전히 여유 CPU가 있는데 커맨드가 누락된다면 더 깊은 조사가 요구됨

조사 결과 태스크 우선 순위(task priorities) 관련 문제가 있음이 밝혀짐(아래 그림 참조)
- 하드웨어 버퍼로부터 커맨드를 읽도록 설계된 Command Processing Task는 오버런을 피하기 위해 매 32 밀리초마다 버퍼를 서비스함. 즉, 하드 데드라인이 32 밀리초
- 또 다른 태스크 Health Monitor Task는 우주선 상의 모든 자율 건강/안전 모니터링을 수행하고 결함 발생 시 시정 조치를 시작시키는걸 책임지고 있음. Health Monitor Task는 초 당 한 번씩만 실행되며 더 긴 실시간 데드라인(1초)을 가짐
- 개발된 소프트웨어에서 Health Monitor Task가 더 높은 우선 순위로 실행되고 있었으며, Command Processing Task를 주기적으로 프리엠션하고 있었음. 즉, 소프트웨어 설계자가 최단 실시간 데드라인을 가진 태스크에 높은 우선 순위를 할당하기 보다는 중요한 태스크(우주선 건강 모니터링)에 더 높은 우선순위를 할당하는 실수를 함. 따라서 Command Processing Task가 굶주리게 되었고 가끔 버퍼를 서비스 하는걸 놓치게 됨. 그 결과 누락된 커맨드가 생겨남
- 조사 후 우선 순위가 수정되고 동일한 서브테스트가 반복되었을 때 모든 1000개 커맨드가 성공적으로 수신되었음. CPU 로딩에 전체적으로 변화가 없었음에도 불구하고 두 태스크 모두 실시간 데드라인을 맞출 수 있었음

결함 사례 #2: 가용 메모리 버퍼가 고갈되었을 때 프로세서가 리셋됨
- 소프트웨어가 모든 가용한 메모리를 고갈시키도록 데이터 입력률을 최대화 하는 서브테스트가 설계됨(시스템에서 태스크에 의해 할당 또는 할당 해제되는 고정 크기의 메모리 버퍼 풀을 포함하는 소프트웨어 구현을 겨냥한 테스트)
- 일반적으로 태스크가 입력 데이터를 저장 및 처리하기 위해 버퍼를 할당하고, 처리가 완료되면 버퍼를 풀어줌. 평소답지 않게 높은 입력이 시스템으로 몰려들면 소프트웨어가 버퍼를 풀어줄 수 있는 것보다 더 빠르게 할당을 하게 되며, 이는 결국 자유로운 버퍼가 없는 상태로 가게 됨
- (버퍼가 가용하지 않으므로) 소프트웨어가 입력 데이터를 누락시킬 것으로 예상되었지만 저하된 오퍼레이션 모드로 실행이 계속되었고, 대신에 버퍼가 고갈되면 프로세서가 리셋되는 것이 관측됨

이 문제의 조사에서 리턴 값이 체크되지 않는 전통적인 프로그래밍 에러가 발견됨(아래 그림 참조)
- 고정 크기 풀의 버퍼를 할당시키기 위해 유틸리티 GetBuffer() 함수가 소프트웨어 전반에서 사용됨. 이 함수가 버퍼가 가용한지 여부를 나타내는 리턴 코드 뿐만 아니라 버퍼로의 포인터를 제공하는데, 소프트웨어의 한 인스턴스에서 리턴 코드를 체크하는게 누락됨. 그 결과 “null” 버퍼가 사용되었고, 임의 메모리가 덮어쓰기 되면서 워치도그 리셋으로 이어짐
- 버퍼를 사용하기에 앞서 리턴 코드를 체크하도록 수정하여 문제 해결. 소프트웨어 전반에 거쳐 GetBuffer()로의 호출 인스턴스가 65건이 있었는데, 적절한 에러 체킹을 하지 않은 유일한 인스턴스가 바로 이 문제를 일으킨 한 건의 인스턴스 였음
- 코드가 수정된 후에 반복된 동일한 테스트에서 의도된 자연스러운 성능 저하가 관측되었음. 즉, 일부 입력 데이터가 소실되었지만 소프트웨어가 계속 동작하였고(robustness), 입력 데이터율이 정상 수준으로 되돌아 왔을 때 완전한 소프트웨어 오퍼레이션이 복구됨(elasticity)

결함 사례 #3: CPU가 높은 부하를 가질 때 예상치 못한 커맨드 거부가 발생함
- CPU가 과부하까지는 아니고 높은 부하를 가지는 동안 소프트웨어로 특정 커맨드를 보내는 스트레스 서브테스트가 설계됨
- 소프트웨어가 커맨드를 수신할 때 그걸 받아들이기에 앞서 커맨드 필드에 대한 내부 일관성 체크(an internal consistency check)를 하는데, 간혹 이 일관성 체크가 실패하여(커맨드가 왜곡되었음을 의미) 소프트웨어가 커맨드를 거부하는 일이 발생함
- 나중에 동일한 커맨드가 소프트웨어로 다시 전송되자 소프트웨어가 해당 커맨드를 유효한(valid) 것으로 받아들임. 이 문제가 무작위로 나타나는 것으로 보임
이 문제의 조사에서 두 개 태스크가 보호되지 않은 동일한 공유 메모리 리소스를 사용하는 것이 드러남(아래 그림 참조)
- Command Processing Task가 커맨드 데이터 인자를 검증하기 위해 메모리의 Stack 데이터 구조를 사용하는데, 더 높은 우선순위의 Health Monitor Task가 이전에 로드된 헬쓰 모니터 체크를 검증하기 위해 동일한 데이터 구조를 사용함. 가끔 더 높은 우선 순위의 Health Monitor Task가 커맨드 검증 중에 있는 Command Processing Task를 프리엠션하는데, 이 때 Health Monitor Task가 Stack을 훼손시킴. 프리엠션 후에 재개된 Command Processing Task는 자신이 처리 중이던 커맨드가 유효하지 않게 된 상황에 직면함
- 두 태스크가 유효성 체크를 수행하는 공통 함수(a common function)를 호출하며 Stack 데이터 구조를 직접 조작하지 않는다는 사실이 문제의 근본 원인을 찾기 더 어렵게 만듬. 이 공통 함수가 정적 Stack 데이터 구조를 사용하기 때문에 재진입(reentrant)이 아님
- 공통 함수를 각자 자신의 Stack 데이터 구조를 가진 두 개의 함수로 분할하는 것으로 문제를 해결함. 동일한 서브테스트가 반복되었고, 소프트웨어가 커맨드를 거부하는 일 없이 예상한대로 동작함

결함 사례 #4: RAM 디스크가 거의 가득 찼을 때 프로세서가 리셋함
- 소프트웨어가 1 기가 바이트 RAM 디스크를 지원하는데(소프트웨어가 이미지 인스트루먼트로부터 고속 과학 데이터를 받아들이고 그걸 디스크에 저장함), RAM 디스크가 완전히 채워질 때까지 이미지 데이터를 생성하는 스트레스 서브테스트가 설계됨
- 디스크가 꽉 차면 소프트웨어가 차후 이미지 데이터는 포기하고 정상 오퍼레이션을 계속할 것으로 예상하였지만, 이 서브테스트 실행에서 RAM 디스크가 수용량의 약 98%에 도달하자 프로세서가 예상치 못하게 리셋되어 버림

- 소프트웨어와 기저 운영체제가 RAM 디스크를 동일 크기의 65,536개 클러스터로 구성함(클러스터 당 16 킬로바이트). 운영체제가 각 클러스터를 ‘사용됨(used)’ 또는 ‘자유로움(free)’으로 표시함. 소프트웨어가 데이터 저장을 위해 새 클러스터를 찾을 필요가 있을 때 free 클러스터의 주소를 반환하는 시스템 콜을 실행시킴

이 문제의 분석에서 RAM 디스크 사용이 그 수용량 한계에 가까워짐에 따라 free 클러스터를 찾는 검색 시간이 거의 기하급수적으로 늘어나는걸 알아냄
- 비어있는 클러스터를 찾기 위해 사용된 알고리즘이 ‘free’로 표시된 클러스터를 발견할 때까지 선형 검색 체킹을 수행함. 이 비효과적인 무차별 검색 알고리즘(brute force search algorithm)을 사용해서 RAM 디스크 사용율이 p일때 free 클러스터를 찾는데 요구되는 평균 시도 수(N)가 아래와 같다.

- 평균 시도 수(즉, free 클러스터를 찾는데 요구되는 시간)이 약 90% 사용 수준에서 극적으로 증가함. RAM 디스크가 90% 사용되었을 때 free 클러스터를 찾기 위한 평균 시도 수(N)가 10이고, 98%가 사용되었을 때는 50번의 시도가 요구되고, 오로지 1개의 free 클러스터가 남았을 때는 터무니없게도 32,768번의 시도가 요구됨. 따라서 비어있던 RAM 디스크에서는 수백 밀리초가 걸렸던 검색 시간이 RAM 디스크가 거의 차 있을 때는 수 초가 걸리게 됨
- 스트레스 서브테스트 동안 RAM 디스크가 점차 채워지면서 free 클러스터를 찾는 검색 시간이 점점 더 길어지게 되고, 이게 다른 태스크들을 굶주리게 만들어 워치도그 리셋으로까지 이어짐
- 해당 검색 알고리즘이 소프트웨어 애플리케이션 코드가 아니라 운영체제에 존재함. 개발 팀이 운영체제 소스 코드에 접근할 수 있고 훨씬 향상된 검색 알고리즘도 알고 있기는 하지만, 소프트웨어 개발 주기 끝 무렵에 운영체제를 변경하는걸 주저하였음. 대신에 해결책으로 RAM 디스크가 95% 이상 사용되지 않도록 유지하는 운영상의 제한(an operational constraint)을 수립하였고, 소프트웨어에는 아무런 변경도 가하지 않음