High Integrity C++ (HIC++ 또는 HICPP)
- Programming Research Limited(PRQA)에 의해 개발된 C++ 프로그래밍 언어를 위한 소프트웨어 코딩 표준
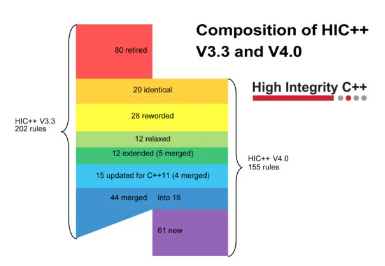
- 2003년 10월 3일, 202개 규칙으로 구성된 HIC++ 코딩 표준 최초 버전이 출시됨
- 2011년 C++ 언어의 주요 변경이 비준됨(ISO C++ 2011)에 따라 HIC++ 코딩 표준도 주요 업데이트가 이루어졌으며, 2013년 10월 155개 규칙으로 구성된 버전 4.0이 출시됨
HIC++ 준수를 체킹하는 자동 도구
- Programming Research Limited가 개발한 QA·C++
- Liverpool Data Research Associates(LDRA)가 개발한 LDRA Testbed/TBvision과 LDRArules
HIC++ 버전 4.0
아래에 주요 규칙의 헤딩만 한글로 나열함. 각각의 상세한 설명과 코드 예는 출처에 나온 웹 사이트 참조
1 일반(General)
| 1.1 구현 준수(Implementation compliance) | 1.1.1 코드가 2011 ISO C++ 언어 표준을 준수해야 한다. |
| 1.2 중복(Redundancy) | 1.2.1 모든 문장(statements)이 도달가능(reachable) 해야 한다. |
| 1.2.2 중복되는 표현(expression) 또는 하위표현(sub-expression)이 없어야 한다. | |
| 1.3 소멸된 기능(Deprecated features) | 1.3.1 bool 타입의 변수 상에 증가 연산자(++)를 사용 안 한다. |
| 1.3.2 register 키워드를 사용 안 한다. | |
| 1.3.3 C 표준 라이브러리 .h 헤더를 사용 안 한다. | |
| 1.3.4 소멸된 STL 라이브러리 기능을 사용 안 한다. | |
| 1.3.5 throw 예외 명세를 사용 안 한다. |
2 어휘 관례(Lexical conventions)
| 2.1 문자 집합(Character sets) | 2.1.1 소스 파일에 탭 문자(tab characters)를 사용 안 한다. |
| 2.2 3중음자(Trigraph sequences) | 2.2.1 이중 글자(digraphs) 또는 3중 글자(trigraphs)를 사용 안 한다. |
| 2.3 코멘트(Comments) | 2.3.1 C 코멘트 구분자 /* … */를 사용 안 한다. |
| 2.3.2 구 코드를 제거하는 대신 코멘트 처리하여 보관하지 않는다. | |
| 2.4 식별자(Identifiers) | 2.4.1 각 식별자가 다른 가시적인 식별자와 확연히 다르다(구별된다). |
| 2.5 리터럴(Literals) | 2.5.1 스트링을 다른 인코딩 접두사(encoding prefixes)와 연쇄하지(concatenate) 않는다. |
| 2.5.2 0을 제외하고는 8진 상수(octal constants)를 사용하지 않는다. | |
| 2.5.3 널 포인터 상수를 위해 nullptr를 사용한다. |
3 기본 개념(Basic concepts)
| 3.1 범위(Scope) | 3.1.1 숨겨진 선언(declarations)을 사용하지 않는다. 동일한 식별자(identifier)를 여러 다른 선언을 위해 재사용하는 것은 혼돈스럽고 유지보수가 어려움 |
| 3.2 프로그램과 링키지(Program and linkage) | 3.2.1 블록 범위에서 함수(functions)를 선언하지 않는다. 모든 선언에서 동일한 타입이 사용되는 것을 보장하기 위해 함수가 항상 네임스페이스 범위에서 선언되어야 함 |
| 3.3 기억 기간(Storage duration) | 3.3.1 정적 기억 기간을 가진 변수(글로벌 변수)를 사용하지 않는다. |
| 3.4 오브젝트 수명(Object lifetime) | 3.4.1 리퍼런스 또는 포인터를 함수 내에 정의된 자동 변수로 반환하지 않는다. |
| 3.4.2 변수 주소를 더 긴 수명을 가진 포인터로 할당하지 않는다. | |
| 3.4.3 리소스를 위해 RAII(Resource Acquisition Is Initialization)를 사용한다. 매니저 클래스를 사용함으로써 리소스의 수명이 정확하게 통제될 수 있음 | |
| 3.5 타입(Types) | 3.5.1 값 또는 오브젝트의 내적 표현(internal representation)에 대한 어떤 가정도 하지 않는다. |
4 표준 전환(Standard conversions)
| 4.1 어레이에서 포인터로 전환(Array-to-pointer conversion) | 4.1.1 함수 인자가 어레이에서 포인터로의 전환을 겪지 않도록 보장한다. |
| 4.2 인테그랄 전환(Integral conversions) | 4.2.1 U 접미사가 무부호 인테그랄 표현식을 요구하는 문맥(context)에 사용되는 리터럴에 적용되는 것을 보장한다. |
| 4.2.2 integral 표현식에서 데이터 손실이 명백히 발생하지 않음을 보장한다. | |
| 4.3 부동 소수점 전환(Floating point conversions) | 4.3.1 더 넓은 부동 소수점 타입의 표현식을 그보다 좁은 부동 소수점 타입으로 전환하지 않는다. |
| 4.4 부동 소수점에서 인테그랄로 전환(Floating-integral conversions) | 4.4.1 부동 소수점 값을 인테그랄 타입으로 전환하지 않는다(표준 라이브러리 함수 사용을 통해서는 예외). |
5 표현식(Expressions)
| 5.1 일차식(Primary expressions) | 5.1.1 코드에서 리터럴 값 대신에 상징적 이름을 사용한다. |
| 5.1.2 한 표현식 내에서 평가의 순서에 의존하지 않는다. | |
| 5.1.3 표현의 의도를 명확히 하기 위해 표현식에서 괄호를 사용한다. | |
| 5.1.4 lambda에서 암묵적으로 변수를 캡쳐하지 않는다. | |
| 5.1.5 모든 lambda 표현식에서 (비어있는) 패러미터 목록을 포함한다. 다른 C++ 구성물(constructs)과의 시각적 애매모호성을 피하기 위함 | |
| 5.1.6 &&, ||, sizeof, typeid, 또는 condition_variable::wait로 전달되는 함수의 우측 피연산자로 부작용(side effects)이 코드되지 않도록 한다. | |
| 5.2 후치식(Postfix expressions) | 5.2.1 포인터 접근 또는 어레이 접근이 명백히 유효한 오브젝트의 경계 내에 있도록 보장한다. |
| 5.2.2 함수가 직접적으로든 간접적으로든 스스로를 호출하지 않음을 보장한다. | |
| 5.3 단항식(Unary expressions) | 5.3.1 무부호 타입(unsigned type)의 피연산자로 단항 마이너스 연산자(-)를 적용하지 않는다. 대신 비트단위 보수 연산자(~) 사용을 선호한다. |
| 5.3.2 메모리를 new를 사용해 할당하고, 그것을 delete를 사용해 할당 해제 한다. | |
| 5.3.3 delete의 형태가 메모리를 할당하는데 사용된 new의 형태와 매치됨을 보장한다. | |
| 5.4 노골적인 타입 전환(Explicit type conversion) | 5.4.1 오로지 static_cast (void* 제외), dynamic_cast, 또는 노골적인 생성자(constructor) 호출의 캐스팅 형태만 사용한다. |
| 5.4.2 표현식을 열거형(enumeration) 타입으로 캐스트 하지 않는다. | |
| 5.4.3 베이스 클래스로부터 파생 클래스로 전환하지 않는다. 이런 캐스트가 불가피하다면 static_cast 보다는 dynamic_cast가 사용되어야 함(컴파일러가 런타임 시 캐스트의 유효성을 체크함) | |
| 5.5 곱셈 연산자(Multiplicative operators) | 5.5.1 division 연산자 또는 remainder 연산자의 우측 피연산자가 명백히 0이 아님을 보장한다. |
| 5.6 시프트 연산자(Shift operators) | 5.6.1 bitwise 연산자를 부호 피연산자(signed operands)와 함께 사용하지 않는다. |
| 5.7 동등 연산자(Equality operators) | 5.7.1 정확한 결과를 내는데 있어 부동 소수점 계산을 기대하는 코드를 작성하지 않는다. |
| 5.7.2 가상 함수 멤버로의 포인터가 오로지 nullptr로만 비교됨을 보장한다. | |
| 5.8 조건 연산자(Conditional operator) | 5.8.1 조건 연산자 (?:)를 하위 표현식(sub-expression)으로 사용하지 않는다. |
6 문장(Statements)
| 6.1 선택문(Selection statements) | 6.1.1 복합문에서 선택문 또는 반복문의 몸체(body)를 둘러싼다. |
| 6.1.2 다중(multi-way) 선택문을 가로지르는 모든 경로들을 명확하게 커버한다. | |
| 6.1.3 비어있지 않은 케이스문 블록이 다음 레이블로 떨어지지 않도록 보장한다. | |
| 6.1.4 스위치문이 디폴트 레이블과는 다른 적어도 두 개의 케이스 레이블을 가짐을 보장한다. 케이스 레이블 수가 2보다 적은 스위치문은 단일 if 문으로 더 자연스럽게 표현될 수 있음 | |
| 6.2 반복문(Iteration statements) | 6.2.1 범위 기반 루프(a range-based loop)로서 오로지 요소 값(element values) 만을 사용하는 루프를 구현한다. |
| 6.2.2 루프가 단일 루프 카운터(하나의 선택적 제어 변수)를 가지며 degenerate가 아님을 보장한다. degenerate 루프란 입력 시 루프가 무한이거나 또는 항상 첫 반복 후 종료되어 버리는 루프를 의미 | |
| 6.2.3 루프에서 제어 변수 또는 카운터 변수를 한번 이상 변경하지 않는다. | |
| 6.2.4 for 표현식에서 오로지 for 루프 카운터만 변경시킨다. | |
| 6.3 점프문(Jump statements) | 6.3.1 점프문 또는 스위치문을 위한 레이블이 동일한 블록에서(또는 둘러싼 블록에서) 나중에 등장함을 보장한다. |
| 6.3.2 non-void 리턴 타입을 가진 함수의 실행이 값을 가진 리턴문에서 끝남을 보장한다. | |
| 6.4 선언문(Declaration statement) | 6.4.1 변수 정의를 최대한 미룬다. |
7 선언(Declarations)
| 7.1 지정자(Specifiers) | 7.1.1 각 식별자(identifier)를 별도 선언의 별도 라인 상에 선언한다. for 루프 초기화 문은 이 규칙에서 면제됨 |
| 7.1.2 가능하면 const를 사용한다. By-value 리턴 타입은 이 규칙에서 면제됨 | |
| 7.1.3 선언에서 타입 지정자(type specifiers)를 non-type 지정자 앞에 놓지 않는다. | |
| 7.1.4 const 한정사(qualifiers) 또는 volatile 한정사를 이것이 적용되는 타입의 우측에 위치시킨다. | |
| 7.1.5 규모가 큰 함수를 인라인(inline)으로 하지 않는다. | |
| 7.1.6 스칼라 양과 표준 정수 타입을 나타내는데 클래스 타입 또는 typedef를 사용한다. | |
| 7.1.7 typename을 사용한 타입 명확화(disambiguation) 보다는 따라 붙는(trailing) 리턴 타입을 사용한다. | |
| 7.1.8 변수를 선언할 때 그 initializer 함수 호출과 동일한 타입을 가지도록 auto id = expr를 사용한다. | |
| 7.1.9 lambda의 리턴 타입을 노골적으로 명세하지 않는다. | |
| 7.1.10 컴파일 타임 상수(constants)와 관련된 어써션을 위해 static_assert를 사용한다. | |
| 7.2 열거형 선언(Enumeration declarations) | 7.2.1 명시적인 열거형 기반(an enumeration base)을 사용하고, 이것이 모든 열거자(enumerators)를 저장할 정도로 충분히 큰 것을 보장한다. |
| 7.2.2 열거 선언에서 아무것도 초기화하지 않거나, 첫 번째 것만 초기화 하거나, 또는 모든 열거자를 초기화한다. | |
| 7.3 Namespaces | 7.3.1 using directive(즉, using namespace)를 사용하지 않는다. |
| 7.4 링키지 명세(Linkage specifications) | 7.4.1 단일 번역 단위(a single translation unit)에서 사용되는 오브젝트, 함수, 또는 타입이 메인 소스 파일의 익명 네임스페이스(an unnamed namespace)에 정의되도록 보장한다. |
| 7.4.2 다수의 번역 단위에서 사용되는 인라인 함수, 함수 템플리트, 또는 타입이 단일 헤더 파일에 정의되도록 보장한다. | |
| 7.4.3 다수의 번역 단위에서 사용되는 오브젝트 또는 함수가 단일 헤더 파일에 선언되도록 보장한다. | |
| 7.5 asm 선언 | 7.5.1 asm 선언을 사용하지 않는다. 코드의 이식성(portability)을 제한하므로 인라인 어셈블리 사용을 피해야 함 |
8 정의(Definitions)
| 8.1 타입명(Type names) | 8.1.1 여러 수준의 포인터 간접참조(indirection)를 사용하지 않는다. |
| 8.2 선언자의 의미(Meaning of declarators) | 8.2.1 모든 선언에서 패러미터명을 부재하도록 만들거나 또는 동일하게 만든다. |
| 8.2.2 지나치게 많은 수의 패러미터로 함수 선언을 하지 않는다. 권고되는 함수 패러미터의 최대 수는 6이다. | |
| 8.2.3 작은 오브젝트는 단순한 값에 의한 복사 생성자(a copy constructor by value)로 전달한다. | |
| 8.2.4 const 참조에 의한 std::unique_ptr 패러미터를 전달하지 않는다. | |
| 8.3 함수 정의(Function definitions) | 8.3.1 지나치게 높은 McCabe 순환 복잡도(Cyclomatic Complexity)를 가진 함수를 작성하지 않는다. 이 메트릭 값이 10을 넘지 않을 것을 권고함 |
| 8.3.2 높은 정적 프로그램 경로 수(static program path count)를 가진 함수를 작성하지 않는다. 정적 프로그램 경로 수는 한 함수에서 비순환적(non-cyclic) 실행 경로들의 수를 의미하며, 단일 함수의 이것이 200을 넘지 않아야 한다. | |
| 8.3.3 디폴트 인자(default arguments)를 사용하지 않는다. | |
| 8.3.4 const로의 rvalue reference 타입 패러미터를 가진 =delete 함수를 정의한다. | |
| 8.4 초기화자(Initializers) | 8.4.1 유효하지 않는 오브젝트 또는 미결정 값(indeterminate value)을 가진 오브젝트에 접근하지 않는다. |
| 8.4.2 중괄호로 둘러싸인 aggregate initializer가 aggregate 오브젝트의 레이아웃에 매치됨을 보장한다. |
9 클래스(Classes)
| 9.1 멤버 함수(Member functions) | 9.1.1 this를 요구하지 않는 멤버 함수를 static으로 선언한다. 아니면 오브젝트의 외적으로 보이는 상태를 변경하지 않는 멤버 함수를 const로 선언한다. |
| 9.1.2 가상 함수(a virtual function)를 오버라이딩할 때 디폴트 인자를 동일하게 만들거나 또는 부재하도록 만든다. | |
| 9.1.3 const 멤버 함수로부터 리턴된 클래스 데이터로 non-const 핸들을 반환하지 않는다. | |
| 9.1.4 멤버 함수보다 적은 접근성을 가지는 데이터로 non-const 핸들을 반환하는 멤버 함수를 작성하지 않는다. Non-const 연산자 []는 이 규칙으로부터 면제됨 | |
| 9.1.5 최종 클래스(a final class)에 가상 함수를 도입하지 않는다. | |
| 9.2 비트 필드(Bit-fields) | 9.2.1 비트 필드를 분명한 무부호(unsigned) 인테그랄 타입 또는 열거형(enumeration) 타입으로 선언한다. |
10 파생 클래스(Derived classes)
| 10.1 다수의 베이스 클래스(Multiple base classes) | 10.1.1 베이스 클래스 하위 오브젝트로의 접근에 있어서 노골적인 모호성 해소(disambiguation)가 필요하지 않음을 보장한다. |
| 10.2 가상 함수(Virtual functions) | 10.2.1 가상 함수를 오버라이딩 할 때 override 특수 식별자를 사용한다. |
| 10.3 추상 클래스(Abstract classes) | 10.3.1 파생 클래스가 많아 봐야 하나의 베이스 클래스(인터페이스 클래스가 아닌 것)를 가짐을 보장한다. |
11 멤버 액세스 제어(Member access control)
| 11.1 접근 지정자(Access specifiers) | 11.1.1 모든 데이터 멤버를 private로 선언한다. extern “C” 블록에서 클래스 키 struct로 선언된 클래스 타입은 이 규칙에 의해 커버되지 않음 |
| 11.2 Friends | 11.2.1 friend 선언을 사용하지 않는다. |
12 특수 멤버 함수(Special member functions)
| 12.1 전환(Conversions) | 12.1.1 암묵적인 사용자 정의(user defined) 전환을 선언하지 않는다. |
| 12.2 소멸자(Destructors) | 12.2.1 베이스 클래스로써 사용되는 타입의 소멸자를 virtual, private, 또는 protected로 선언한다. |
| 12.3 메모리 할당과 해제(Free store) | 12.3.1 operator new와 operator delete를 위한 오버로드를 정확하게 선언한다. |
| 12.4 베이스 클래스와 멤버의 초기화(Initializing bases and members) | 12.4.1 오브젝트가 완전히 생성된 경우가 아니라면 오브젝트의 동적 타입을 사용하지 않는다. |
| 12.4.2 생성자가 모든 베이스 클래스와 비정적(non-static) 데이터 멤버를 노골적으로(explicitly) 초기화함을 보장한다. | |
| 12.4.3 동일한 비정적 멤버를 위해 생성자에 비정적 데이터 멤버 초기화자(non static data member initializer)와 멤버 초기화자(member initializer) 양쪽 모두를 명세하지 않는다. (이 규칙이 Rule 12.4.2와 충돌하므로 이동/복사 생성자는 이 규칙에서 면제됨) | |
| 12.4.4 멤버들을 초기화 목록(an initialization list)에 그것들이 선언된 순서대로 작성한다. | |
| 12.4.5 코드 중복을 줄이기 위해 위임 생성자(delegating constructors)를 사용한다. | |
| 12.5 클래스 오브젝트의 복사 및 이동(Copying and moving class objects) | 12.5.1 구체 클래스(concrete classes)의 암묵적 특수 멤버 함수를 =default 또는 =delete로 명확하게 정의한다. |
| 12.5.2 동작이 동일하다면 특수 멤버를 =default로 정의한다. | |
| 12.5.3 사용자 정의의 이동/복사 생성자가 오로지 베이스 및 멤버 오브젝트를 이동/복사함을 보장한다. | |
| 12.5.4 이동 생성자와 이동 할당 연산자를 noexcept로 선언한다. | |
| 12.5.5 moved-from 핸들을 이동 생성자의 리소스로 정확하게 리셋한다. 이것의 가장 흔한 예가 포인터 멤버로 nullptr를 할당하는 것이다. | |
| 12.5.6 복사/이동 할당 연산자를 구현하기 위해서 원자성의(atomic) non-throwing 교환 연산(swap operation)을 사용한다. | |
| 12.5.7 할당 연산자를 참조 한정자(ref-qualifier) &로 선언한다. | |
| 12.5.8 추상 클래스(abstract class)의 복사 할당 연산자를 protected로 만들거나, 또는 그것을 =delete로 정의한다. |
13 오버로딩(Overloading)
| 13.1 오버로드 결정(Overload resolution) | 13.1.1 어떤 함수의 모든 오버로드가 해당 함수가 호출되어지는 위치에서 가시적임을 보장한다. |
| 13.1.2 만약 호출가능한 함수들의 집합의 한 멤버가 보편적 참조 패러미터(a universal reference parameter)를 포함한다면, 이것이 모든 다른 멤버들을 위한 동일한 위치에 등장함을 보장한다. | |
| 13.2 오버로드된 연산자(Overloaded operators) | 13.2.1 특별한 시맨틱을 가진 연산자를 오버로드 하지 않는다. |
| 13.2.2 오버로드된 2진 연산자의 리턴 타입이 상응하는 빌트인 연산자의 리턴 타입과 매치함을 보장한다. | |
| 13.2.3 오버로드된 2진 산술 연산자와 비트와이즈 연산자를 비멤버(non-members)로 선언한다. | |
| 13.2.4 첨자 연산자(operator[])를 오버로딩할 때는 const 버전과 non-const 버전 둘 다를 구현한다. | |
| 13.2.5 연산자들의 최소한의 집합을 구현하고, 이것들을 모든 다른 관련 연산자들을 구현하는데 사용한다. |
14 템플리트(Templates)
| 14.1 템플리트 선언(Template declarations) | 14.1.1 ellipsis 템플리트 보다는 variadic 템플리트를 사용한다. 만약 variadic 템플리트 사용이 가능하지 않다면, 함수 오버로딩 또는 함수 호출 연쇄(function call chaining)가 고려되어야 한다. |
| 14.2 템플리트 인스턴스화와 특수화(Template instantiation and specialization) | 14.2.1 템플리트 특수화를 특수화 하고자 하는 기본 템플리트(primary template)와 동일한 파일에 선언한다. |
| 14.2.2 다른 템플리트로 오버로드 되는 함수 템플리트를 노골적으로 특수화하지 않는다. | |
| 14.2.3 노골적으로 인스턴스화된 템플리트를 extern으로 선언한다. |
15 예외 처리(Exception handling)
| 15.1 예외 발생시키기(Throwing an exception) | 15.1.1 예외 발생에 오로지 std::exception의 인스턴스 만을 사용한다. |
| 15.2 생성자와 소멸자(Constructors and destructors) | 15.2.1 소멸자에서 예외를 발생시키지 않는다. |
| 15.3 예외 처리하기(Handling an exception) | 15.3.1 생성자/소멸자의 try 블록의 catch 핸들러로부터 비정적(non-static) 멤버에 액세스하지 않는다. |
| 15.3.2 프로그램이 std::terminate 호출을 하는 결과를 낳지 않음을 보장한다. |
16 전처리(Preprocessing)
| 16.1 소스 파일 포함(Source file inclusion) | 16.1.1 전처리기를 오로지 include guard를 구현하는데(즉, include guard를 가진 헤더 파일을 포함시키는데) 사용한다. 동일한 파일이 다수 포함(multiple inclusions)되는걸 막기 위해 include guard가 각 헤더 파일에 존재해야 함 |
| 16.1.2 #include 지시어(directives)에 주어지는 파일명에 경로 지정자(a path specifier)를 포함시키지 않는다. | |
| 16.1.3 #include 지시어(directives)에 있는 파일명을 파일 시스템 상의 그것과 매치시킨다. 일부 운영체제가 대소문자 구별이 없는 파일 시스템을 가지는데, 애초에 이런 시스템 상에서 개발된 코드가 대소문자를 구별하는 파일 시스템으로 이식될 때 성공적으로 컴파일 되지 못할 수도 있음 | |
| 16.1.4 시스템 및 표준 라이브러리 헤더를 위해서 <> 괄호를 사용한다. 모든 다른 헤더를 위해서는 따옴표를 사용한다. 컴파일러 제공 헤더를 위해서는 #include <…>가 쓰이고, 사용자 제공 파일을 위해서는 #include “…”가 사용되는 것이 일반적인 관행 | |
| 16.1.5 컴파일에 필요한 최소한의 수의 헤더를 직접적으로 포함시킨다. 필수적이지 않은 include directives의 존재가 대규모 코드 베이스의 컴파일을 상당히 느려지게 할 수 있으므로, 소스 파일 리팩터를 할 때에 포함된 헤더 목록을 검토하여 더 이상 필요하지 않은 include directives를 제거해야 함 |
17 표준 라이브러리(Standard library)
| 17.1 일반(General) | 17.1.1 std::vector<bool>을 사용하지 않는다. |
| 17.2 C 표준 라이브러리 | 17.2.1 C 표준 라이브러리가 사용되는 경우 그것을 wrapper로 감싼다. 이 wrapper가 미정의 동작(undefined behavior)이나 데이터 경쟁(data races)이 발생하지 않도록 보장 해 줌 |
| 17.3 일반 유틸리티 라이브러리(General utilities library) | 17.3.1 const 또는 const & 타입으로 선언된 오브젝트 상에 std::move를 사용하지 않는다. |
| 17.3.2 보편 참조(universal references)를 포워딩하는데 std::forward를 사용한다. | |
| 17.3.3 std::forward로의 전달인자(argument)를 나중에 사용하지 않는다. 함수 호출에 사용된 인자들의 값 범주에 따라 std::forward가 패러미터 이동을 시킬 수도 또는 안 시킬 수도 있음. 패러미터의 값 범주가 lvalue 일 때는 패러미터의 변경이 호출자(caller)의 인자에 영향을 주며, rvalue인 경우는 std::forward 호출 후에 값이 미정(indeterminate)인 것으로 여겨져야 함 | |
| 17.3.4 어레이 타입의 스마트 포인터를 생성하지 않는다. | |
| 17.3.5 std::array의 rvalue 참조(reference)를 생성하지 않는다. | |
| 17.4 컨테이너 라이브러리(Containers library) | 17.4.1 결과가 즉시 const iterator로 전환될 때 const 컨테이너 호출을 사용한다. |
| 17.4.2 오브젝트를 제자리에(사용이 의도된 위치) 구축하는 API 호출을 사용한다. | |
| 17.5 알고리즘 라이브러리(Algorithms Library) | 17.5.1 std::remove, std::remove_if 또는 std::unique의 결과를 무시하지 않는다. 대개의 경우 올바른 동작은 이 결과를 std::erase로의 호출에서 첫 번째 피연산자로써 사용하는 것이다. |
18 동시성(Concurrency)
| 18.1 일반(General) | 18.1.1 어떤 특정 플랫폼에 한정된 멀티쓰레딩 기능을 사용하지 않는다. |
| 18.2 쓰레드(Threads) | 18.2.1 std::thread 대신에 high_integrity::thread를 사용한다. |
| 18.2.2 쓰레드 간 공유되는 데이터로의 액세스를 단일 잠금(lock)을 사용하여 동기화한다. | |
| 18.2.3 쓰레드 간에 휘발성(volatile) 데이터를 공유하지 않는다. | |
| 18.2.4 더블 체킹 잠금 패턴(Double-Checked Locking pattern) 보다는 std::call_once를 사용한다. | |
| 18.3 상호 배제(Mutual Exclusion) | 18.3.1 어떤 잠금(lock)의 범위 내에서 동일 뮤텍스의 잠금이 되는 정적 경로가 없음을 보장한다(쓰레드가 자신이 이미 소유한 std::mutex를 잠그려 하는 시도를 피해야 함). |
| 18.3.2 한 프로젝트에서 잠금의 포개어진(nesting) 순서가 방향성 비사이클 그래프(a Directed Acyclic Graph)를 형성함을 보장한다. | |
| 18.3.3 std::recursive_mutex를 사용하지 않는다. | |
| 18.3.4 std::lock_guard가 사용될 수 없을 때에만 std::unique_lock을 사용한다. std::unique_lock 타입이 std::lock_guard에서는 가용하지 않은 추가적인 기능을 제공하므로 이를 사용하는데 있어 추가적인 비용이 따른다. | |
| 18.3.5 std::mutex의 멤버에 직접 액세스 하지 않는다. 뮤텍스 오브젝트는 오로지 그것을 소유한 std::lock_guard 또는 std::unique_lock 오브젝트에 의해서만 관리되어야 한다. | |
| 18.3.6 완화된 원자(relaxed atomics)를 사용하지 않는다. | |
| 18.4 조건 변수(Condition Variables) | 18.4.1 std::mutex 상에 std::condition_variable_any를 사용하지 않는다. |