관계형 데이터베이스에 저장된 데이터에 접근하는 데 쓰이는 SQL 쿼리를 테스트하기 위한 가이드라인을 제안한 자료(MC/DC 커버리지나 카테고리 분할 같은 기존의 잘 알려진 테스팅 기법을 SQL에 적용함).
제안하는 가이드라인을 설명하기 위해 간단한 데이터 모델과 SQL 쿼리(버그가 포함된 쿼리)를 예로 들고, 이 쿼리를 위한 테스트케이스(테스트 상태)를 가이드라인에 따라 설계하고, 설계된 테스트케이스로 쿼리에 존재하는 4개의 버그를 찾아 수정하는 것을 보여준다.
SQL 쿼리를 테스팅 하는 데 있어서의 특이점
- SQL은 절차적 언어가 아니며, 따라서 프로그램에는 절차적 코드(예, Java)와 비절차적 코드(SQL)가 혼합되어 있다.
- 쿼리가 두 가지 다른 종류의 입력을 가지며(패러미터, 데이터베이스 테이블에 저장된 복잡한 데이터 구조 세트), 이는 입력 공간(input space)를 매우 커지게 만든다.
- 출력이 테이블 형식이며, 이게 테스트 예상 결과를 결정하는 일을 복잡하게 한다.
- 데이터베이스 쿼리 프로세싱이 데이터베이스 스키마(즉, 구조와 제약조건)에 크게 의존하므로, 여기에 작은 변경이라도 발생하면 많은 쿼리의 동작이 바뀔 수 있다.
- 디시젼(decision)이 부울 로직(Boolean logic) 대신 3가 로직(three-valued logic)을 사용한다. 프로그래머가 이를 제대로 인지하지 못하는 경우, 미정의 값(undefined values)을 포함하는 데이터베이스 필드가 때때로 예기치 못한 동작을 한다.
- 테스트케이스를 설계할 때 테스터가 쿼리를 실행하는 다양한 상황이나 데이터베이스 상태를 식별해야 한다. 테스터는 데이터베이스 로드(load) 수를 작게 유지하기 위해 각 단일 테스트케이스에 상당히 많은 데이터베이스 상태를 포함시키고자 노력하며, 따라서 명령형(imperative) 프로그램의 테스트와 비교하여 일반적으로 더 적지만 더 복잡한 테스트케이스를 가지게 된다.
- 데이터베이스 테스트스위트의 완전성(completeness)을 평가하고 테스터의 테스트케이스 개발을 안내하는데 쓸 수 있는 ‘적절성 기준(adequacy criteria)’이 부족하다.
SQL이 수행하는 주요 프로세싱은 하나 또는 하나 이상의 테이블에서 데이터 행(rows)을 선택하고 결합하는 것이다. select 절은 어떤 필드(열)가 쿼리 출력을 구성하는지 결정하고, from 절은 어떤 테이블이 사용되는지 결정하고, join은 여러 다른 테이블의 행을 결합하는 기준(join-조건)을 결정한다. where 절은 주어진 기준(where-조건)에 따라 행을 필터링한다. group by 절은 선택된 행을 어떻게 종합하는지를 나타내며, having 절은 기타 다른 조건(having-조건)에 따라 최종 필터링을 수행한다. 추가적으로 order by 절은 출력할 결과 집합을 어떻게 정렬하는지 결정한다.
Example: 버그가 포함된 SQL 쿼리 예
데이터 모델(Data Model)
이 데이터베이스는 프로젝트(project), 직원(employee), 각 직원이 특정 프로젝트에서 일한 월별 시간(work)에 대한 정보를 저장한다. 그림에 표시된 대로 기본 키(primary key)와 외래 키(foreign key) 제약이 존재하며, 모든 값이 유효한 값이고 그 도메인 내에 있다고 가정한다. 또한 정수(Integer) 값들이 양수라고 가정한다.
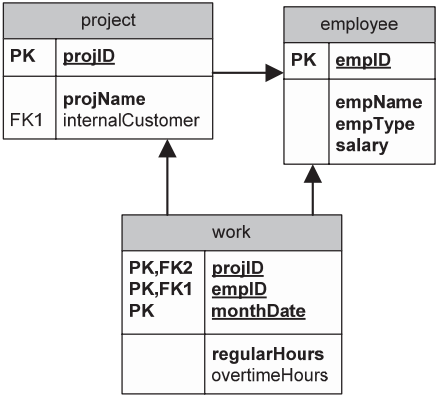
각 테이블의 필드 정보가 아래와 같다.
| project | projID: int not null, 각 프로젝트의 고유 식별자. projName: char(32) not null, 프로젝트의 서술형 이름. internalCustomer: int, 프로젝트의 고객이 직원인 경우 이 필드가 해당 직원의 ID를 저장한다. |
| employee | empID: int not null, 각 직원의 고유 식별자. empName: char(32) not null, 직원의 성명. empType: char(1) not null, 직원 카테고리(P: 프로그래머, M: 관리자). salary: int not null, 월 급여(US $). |
| work | monthDate: char(6) not null, 근로 기록의 월을 나타내며 yyyymm 형식이다. regularHours: int not null, 직원이 한 달 간 프로젝트에서 일한 총 정규 시간 수. overtimeHours: int, 직원이 한 달 간 프로젝트에서 일한 총 초과 근무 시간 수. |
정보 요청(Information Request)
경영진이 알고 싶은 정보는 정규 근무 시간 수가 총 근무 시간 수의 95% 미만인 프로젝트와 해당 프로젝트의 근무 시간 수(정규 근무 및 초과 근무 모두)이다. 이 때 오로지 프로그래머가 일한 근무 시간 또는 월 급여가 $3,000를 초과하지 않는 직원이 일한 근무 시간만 고려한다(이들이 어느 프로젝트에서도 내부 고객이 아니라는 전제 하에).
위 요청에 대해 개발자가 다음과 같은 SQL 쿼리를 작성했다고 가정한다(주의: 이 쿼리에 다수의 버그가 포함되어 있는데, 이를 찾아낼 수 있는가?).

SQL 테스트케이스 설계를 위한 5가지 가이드라인
버그가 포함된 위 SQL 쿼리에 체계적인 테스트를 수행하기 위하여 다음의 5가지 지침을 따른다.
1. SQL 조건절에 MC/DC 커버리지 적용(Adopting MC/DC for SQL conditions)
SQL 쿼리는 조회할 데이터에 대한 디시젼을 세 군데(join, where, having 조건절)에서 수행한다. 이를 ‘일련의 순차 필터’ 또는 ‘여러 조건의 결합으로 구성된 디시젼’으로 간주할 수 있으며, 따라서 테스트 설계를 위해 제어 흐름 기반 기준(control-flow based criterion)을 채택하는 것이 합리적이다. 테스트가 실제 출력과 예상 출력의 비교를 통해서만 결함을 드러낼 수 있기 때문에, 어떤 조건을 커버하도록 설계된 테스트가 다른 조건에 의해 가려지는 것을 방지하는 것이 중요하다. 예를 들어 테스트가 where 절에 있는 다중 조건 기준을 충족하는 경우, where-조건에 의해 선택된 행이 이후에 having-조건에 의해 폐기되면 이 테스트가 쓸모 없게 된다.
우리가 적용할만한 합리적인 기준으로 RTCA/DO-178B 표준에 정의된 MC/DC(the Modified Condition Decision Coverage)가 있는데, 이 기준이 테스트 집합 크기(test-set size)와 오류 감지 능력(fault detecting ability) 간의 좋은 균형을 보이는 것으로 입증되었다. MC/DC가 요구하는 기준은 “모든 조건이 가능한 모든 결과를 최소 한 번 이상 취해야 하며, 각 조건이 디시젼의 결과에 독립적으로 영향을 미쳐야 한다(every condition has taken all possible outcomes at least once, and each condition has been shown to independently affect the decision’s outcome)” 이다.
각 ‘복합 AND 조건(compound AND condition)’에서 모든 조건이 참(true)이 되는 테스트 상태가 필요하고, 또한 이 조건 중 각각 하나씩만 거짓(false)으로 평가되는 테스트 상태들도 추가적으로 필요하다. OR 조건의 경우 모든 조건이 거짓(false)이 되는 테스트 상태가 필요하고, 또한 각 조건 하나만 참(true)으로 평가되는 테스트 상태들도 추가적으로 필요하다.
다른 주요 SQL 문(즉, update, insert, delete)이 종종 select 및 where 절을 포함하므로, 여기에도 이런 가이드라인을 적용해야 한다.
아래 ‘테스트케이스 설계 섹션’의 ‘파트 A’는 위의 기준을 적용하여 주어진 예제 쿼리를 위한 테스트케이스를 설계한 예를 제공한다.
2. null을 처리하기 위해 MC/DC 조정(Adapting MC/DC for tackling with nulls)
SQL의 ‘알 수 없는 값(null)’ 처리는, 개발자가 이를 제대로 알지 못하면, 때때로 악몽으로 변하기도 한다. 예를 들어, a AND b 형식의 where-조건은 a 또는 b가 ‘unknown’으로 평가될 때 그 결과로 ‘unknown’을 반환하며, 이는 만일 ‘참(true)’으로 평가되었다면 결과로 포함되었을 행을 결과 집합에서 제외되도록 만든다. 쿼리가 null을 어떻게 처리해야 하는 지는 비즈니스 측면에서 그 정확한 의미에 달려 있다(예, 아직 알려지지 않았지만 미래에 알게 될 수도 있는 값, 절대 알 수 없는 값, 관련이 없거나 또는 해당 없는 값). 따라서 가능하면 null을 실행하는 테스트를 포함할 필요가 있다.
MC/DC 기준에서 사용하는 부울 로직(Boolean logic)을 3가 로직(a three-valued logic)으로 전환해야 한다. 예를 들어, a AND b 형식의 복합 조건의 경우 각각 하나가 ‘null’이고 다른 하나는 ‘참(true)’인 두 개의 추가적인 테스트 상태가 필요하다.
만일 조건이 둘 이상의 열 참조(column reference)로 구성된 경우라면, 이들 각각을 ‘null’로 만드는 동시에 다른 것들은 ‘null’이 아니도록 만든 테스트 상태를 추가해야 한다. join-조건의 경우 null 값은 아래의 두 가지 다른 이유로 나타난다(후자가 더 빈번함).
a) 조인된 열이 데이터베이스에서 null이다.
b) 불완전한 join(즉, left join, right join, outer join)의 결과로 null 값이 생성되었다.
아래 ‘테스트케이스 설계 섹션’의 ‘파트 B’는 null을 고려한 테스트케이스 설계의 예를 보여준다.
3. 선택되는 데이터에 카테고리 분할 적용(Category partitioning selected data)
SQL 쿼리를 “짧은 형식의 선언적 명세(a short formal declarative specification)”로 간주하고, 여기에 일종의 명세 기반 테스팅 방법(예, Category Partition 방법)을 적용할 수 있다. 즉, 데이터에 관한 카테고리 집합을 정의하고, 각 카테고리에서 선정된 값들을 테스트 입력으로 하는 것이다. SQL에 다음과 같은 카테고리 집합을 적용할 수 있다.
- 조회되는 행(Rows that are retrieved): 쿼리가 선택할 수 있는 행이 하나도 없도록 만드는 테스트 상태를 설계한다. 이것이 항상 결과 집합이 비어 있는(empty set) 것을 의미하지는 않는다. 출력에 집계 함수(aggregate functions)가 포함된 쿼리의 경우, 쿼리가 어떤 행도 선택하지 않으면 count 함수는 0을 그리고 다른 집계 함수는 null을 결과 집합으로 반환한다.
- 병합되는 행(Rows that are merged): 출력에 원하지 않는 중복 행(duplicate rows)이 존재하는 것은 쿼리에서 자주 볼 수 있는 실패이다. 따라서 동일한 행이 선택되도록 만드는 테스트 상태를 설계한다. 이 때 select 절은 완전히 동일한 행을 모두 출력하는 반면, select distinct은 중복을 제거하고 출력한다. 이는 쿼리의 union에서도 마찬가지인데, union 절이 중복 행이 나오는 것을 방지하는 반면, union all 절은 중복을 포함한 모든 행을 대상으로 한다.
- 그룹화되는 행(Rows that are grouped): group-by 필드 각각에 대해 최소한 두 개의 다른 그룹이 출력에 나타나도록 만드는 테스트 상태를 설계한다(그룹화하는데 쓰인 값은 동일하고 그 외 나머지는 모두 다르도록 함). null 값은 행을 그룹화할 때 하나의 독립적인 값으로 간주된다. 따라서 group-by 필드 각각에 대해서 적어도 하나의 null 그룹(그 외 나머지는 모두 null이 아니도록 함)을 생성하는 테스트 상태를 포함해야 한다.
- 서브쿼리에서 선택되는 행(Rows that are selected in a subquery): 각 서브쿼리에 대해 0개 이상의 행을 반환하는 테스트 상태를 설계한다(선택된 열에 하나 이상의 null과 두 개의 서로 다른 값이 존재하도록 만듬). 또한 all, any, some이 사용된 서브쿼리를 위한 추가적인 테스트 상태도 포함한다.
- 집계 함수에 참여하는 값(Values that participate in aggregate functions): 각 집계 함수(count 제외)에 대해 하나 이상의 테스트 상태를 설계한다. 이 때 함수가 두 개의 동일한 값과 하나의 다른 값을 계산하도록 하는데, 이는 함수가 유한 값(distinct values)을 다루는 경우와 구별할 수 있게 만든다. 또한 각 집계 함수가 null 값을 계산하는 경우도 반드시 추가해야 한다.
- 기타 표현식(Other expressions): 카테고리 분할 및 경계값 체킹 기법을 사용하여 여러 표현식(예, like 프레디킷, date 관리, 스트링 관리, 데이터 타입 전환, 기타 함수)을 위한 테스트 상태를 설계한다.
아래 ‘테스트케이스 설계 섹션’의 ‘파트 C’는 위의 가이드라인에 따라 예제 쿼리의 테스트케이스를 설계한 것이다.
4. 출력 확인(Checking the outputs)
경험에서 나온 상식적인 테스트케이스 설계법으로 출력 도메인에서 유효 값과 유효하지 않은 값을 체킹하는 방법이 있다. 변수 도메인에는 null 값도 속해 있으므로, 쿼리 결과 집합의 각 열에 null 값이 있는 행을 선택하도록 만드는 테스트 상태를 설계해야 한다. 프로그램 변수에 저장되는 데이터베이스 null의 동작이 호스트 언어에 크게 의존하며 SQL에서의 null 동작과 일치하지도 않으므로, 이러한 종류의 테스트가 매우 중요하다.
예를 들어, 아래는 데이터베이스 테이블에 저장된 ‘도시’와 ‘온도(섭씨)’를 한 행씩 불러와서 화씨 온도로 변환해 출력하는 프로그램 예이다(버그가 포함되어 있음).

쿼리가 데이터베이스에서 가져온 어떤 행의 온도가 null이면 Java 프로그램의 celsius 변수 값이 0.0이 되며, 이는 화씨 32.0도로 잘못 변환된다. 프로그램이 wasNull() 메쏘드를 사용하여 해당 값의 null 여부를 체크하고, null인 경우 계산을 건너뛰도록 했어야 한다.
Visual Basic 구현은 좀 다르게 동작하는데, 유효하지 않은 캐스트 예외(invalid cast exception)로 인한 실패가 발생한다. 이 경우 null 값이 어떤 유효한 값도 제공하지 않으며, Celsius 변수는 실패를 일으키는 DBNull이라는 특수 값을 저장한다. 앞의 경우와 마찬가지로 이 프로그램도 Convert.IsDBNull() 함수를 사용하여 값의 null 여부를 체크했어야 한다.
5. 데이터베이스 제약 조건 확인(Checking the database constraints)
여기에 기술된 많은 테스트 상태가 데이터베이스 제약으로 인해 불가능할 수 있다. 개발 중에 데이터베이스 스키마를 변경하는 일이 꽤 빈번한데, 이런 변경으로 인해 제약 조건이 증가하면 설계된 테스트케이스가 데이터 로드 중에 설정(set-up)에 실패할 수도 있다. 반면 변경으로 인해 제약 조건이 감소하면 테스트케이스를 설계할 때 일부 상황이 실행되지 않았기 때문에 테스트케이스가 불완전해질 수 있다. 가정된 모든 제약 조건이 데이터베이스에서 시행되는지 확인하기 위한 추가적인 테스트케이스를 포함해야 하며, 모든 종류의 제약 조건을 확인해야 한다(예: 중복 기본 키를 가진 레코드 삽입, 참조 무결성을 위반하는 레코드 삽입 및 삭제, not null 필드에 null 값 삽입, 도메인을 벗어나는 값으로 필드 업데이트).
SQL 쿼리를 위한 테스트케이스 설계 예
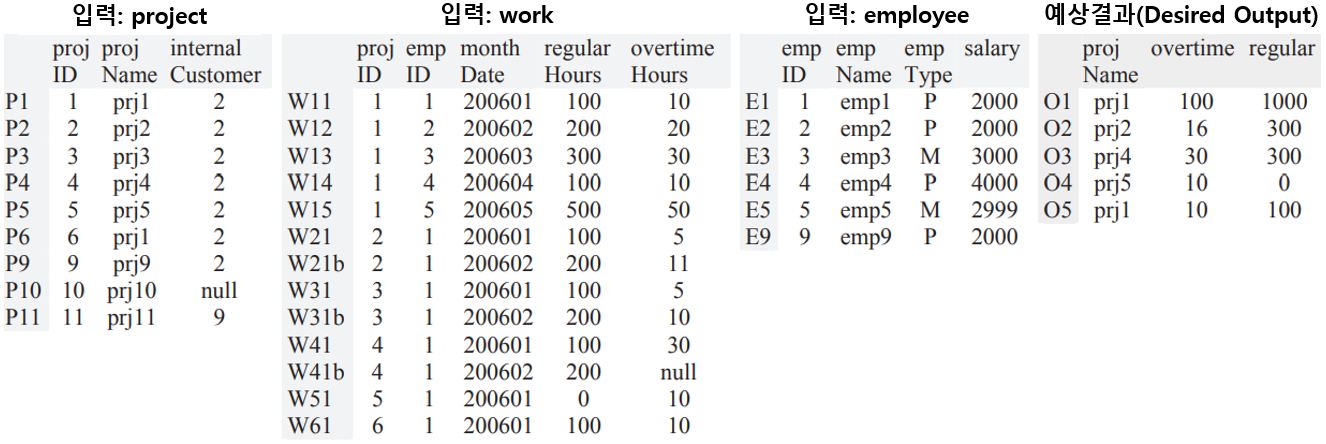
앞에서 예로 제시된 SQL 쿼리를 테스트하기 위해 설계한 테스트케이스(입력데이터 및 예상결과)가 아래와 같다.
NOTE.
- 각 테이블의 맨좌측에 붙은 번호(P1, W11, E1, O1 등등)는 데이터베이스 필드가 아니라 각 테스트 데이터 행(레코드)을 구별하기 위해 추가한 테스트케이스 식별자(ID)이다.
- project 테이블에서 projID가 6인 프로젝트의 이름이 ‘proj1’인 것은 오타가 아니라 의도적으로 중복된 프로젝트명의 테스트 데이터를 설계한 것이다.
위 테스트케이스 설계의 이론적 해석(근거)이 아래와 같다.
파트 A: null이 없는 조건
| – E1, E2, P1, W11: 모든 조건이 참(true)인 경우를 커버하기 위해 추가된 행들이다. – E3, E4, E5, W13, W14, W15: OR의 where-조건을 커버하기 위해 추가된 행들이다. – W12: 서브쿼리의 where-조건을 커버하기 위해 추가된 행이다. – P9: 첫 번째 join-조건을 커버하기 위해 추가되었다. 또 다른 join-조건은 이미 커버됨. – P2, W21, W21b, P3, W31, W31b: (경계에 있는) having-조건을 커버하기 위해 추가되었다. |
파트 B: null이 존재하는 조건
| – E9: 두 번째 join의 null 조건을 커버하기 위해 근무 기록이 없는 직원을 추가하였다. 다른 조건들은 이미 커버되었거나 또는 참조 무결성 제약에 의해 막힘 – P10: 서브쿼리의 null 조건을 커버하기 위해 internalCustomer가 없는 프로젝트를 추가하였다(이는 서브쿼리가 null 값을 반환하도록 만든다). – P4, W41, W41b: having 조건의 null을 커버하기 위해 추가되었다(이는 having 조건의 총 시간이 null로 반환되도록 만든다). |
파트 C: 기타
| – 0개 행이 출력되는 결과를 얻으려면 W13을 제외한 모든 work 레코드를 제거하여 새로운 독립적인 테스트케이스를 추가한다. – P6, W61: 두 개의 프로젝트가 같은 그룹에 병합된다(둘이 같은 프로젝트명을 가지고 있음). – 그룹화된 행들과 집계 함수에 있는 값들이 이미 커버되었다. – P11: 서브쿼리가 여러 다른 값들을 반환하도록 만들기 위해 추가되었다. – P5, W51: 출력에서 정규 근무 시간이 0이 되도록 만든다. having-조건으로 인해 다른 0 값과 null 값은 불가능하다. |
실습
주어진 데이터 모델에 따라 MySQL에서 테이블을 생성하고, 위 설계된 테스트 입력 데이터로 테이블을 채워 SQL 쿼리를 실행해 보면 테스트 예상 결과가 출력되지 않는다. 즉, SQL 쿼리가 신택스 에러 없이 정상적으로 실행은 되지만, 테스트케이스 설계 시 기대했던 결과가 아닌 아래와 같이 해당하는 튜플이 하나도 없는 빈(empty) 결과가 나온다. 쿼리가 의도한 정보를 반환하지 못하므로 결함이 있는 것을 암시한다.
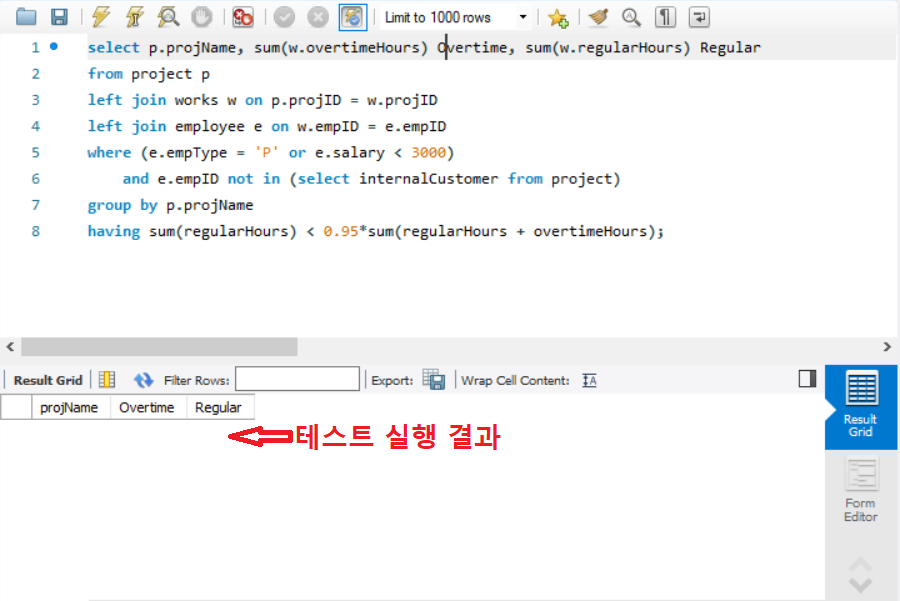
쿼리 예에서 발견한 결함
위에서 제시한 테스트케이스를 실행하여 쿼리에서 찾아낸 4개의 버그가 다음과 같다. 모두 프로그래머가 쿼리를 작성할 때 흔히 범하는 오류이며, 그 중 세 가지는 SQL에만 해당된다.
| 실패(Failure detected) | 결함(Fault) | 버그 수정(Bug fix) | |
| 1 | 쿼리에 급여(salary)가 3,000인 직원은 포함되지 않는다. | OR의 where 조건이 잘못됨 | < 대신 <=를 쓴다. |
| 2 | 프로젝트의 내부 고객이 없는 경우 빈(empty) 쿼리 결과가 나온다. | 서브쿼리가 null을 반환하면 NOT IN 프레디킷이 절대 ‘참(true)’을 반환하지 않음 | 서브쿼리에 아래의 where-조건을 추가한다. internalCustomer is not null |
| 3 | 초과 근무 시간(overtime hours)이 없는 근무 레코드를 고려하지 않았다. | 레코드의 overtimeHours에 null이 있는 경우 이번 달의 총 근무 시간 수가 null로 집계됨 | 해당 필드를 아래처럼 coalesce 프레디킷으로 묶는다. coalesce(overtimeHours,0) |
| 4 | 같은 이름을 가진 두 프로젝트 정보가 동일 그룹으로 병합된다. | 그룹화(grouping)가 오로지projName 필드에서만 수행됨 | group by 절에 projID 필드를 추가한다. |
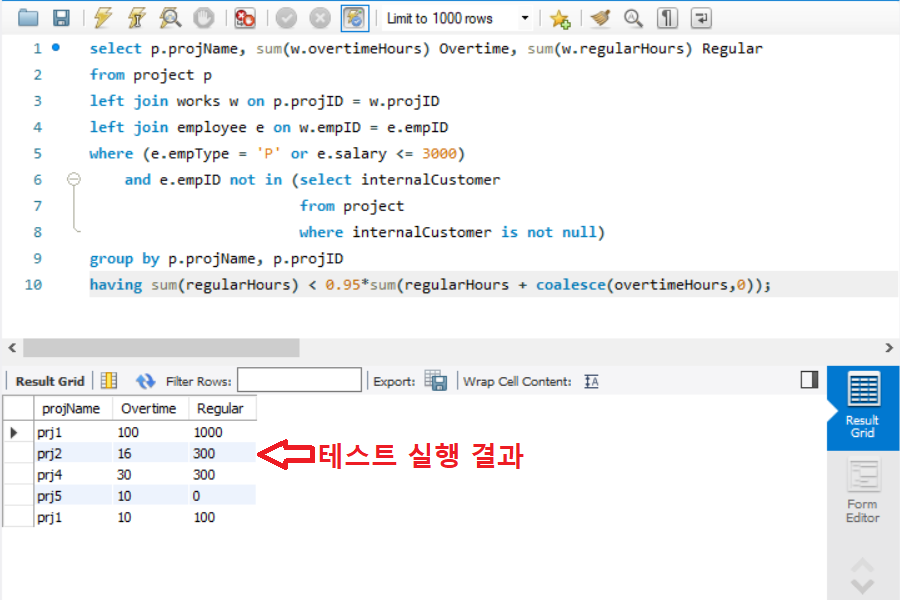
위에 기술된 대로 버그를 수정하고 쿼리를 실행하면 아래와 같이 테스트케이스 예상 결과와 일치하는 실행 결과가 나온다.
결론
제시된 가이드라인은 잘 알려진 기존 테스팅 기법을 SQL에 맞게 각색한 것이며, 쉽고 간단하게 사용가능하다. 이를 체계적으로 적용하면 실무자가 쿼리의 더 완전한 단위 테스트를 달성하는 데 도움이 되고, SQL 작성 및 테스트에 대한 교육에도 활용할 수 있다.